最近呢,我有点愁该如何送我的女神礼物,于是就在想自己设计一个推荐算法,想着先抓取市场上的美妆产品,然后拿下来搞点事情。
选择了考拉海购和小红书,这期间也遇到了一些些小问题,学习到了一些基础的爬虫技术,拿出来分享一下。
因为之前有人跟我说了一下想爬点评的数据,我在github上调研过一下相关的crawler,找到了一个点评爬虫,然后从这份代码中学习一点东西,应用在自己的代码中。
本文将主要讲述一些不需要登录就能够获取到的公共信息的抓取方法和工具,给出一些推荐的理由以及工具的对比。
0x01 puppeteer
https://github.com/GoogleChrome/puppeteer
puppeteer是一款chrome浏览器的nodejs模拟器,可以用它的api,在命令行进行浏览器的操作。puppeteer并不能算作是一款爬虫工具,比爬虫来说,应该更加强大一些,也可以做些跟前端e2e测试有关的事情。
一个电商网站通常是由很多请求组成的,一般都会先请求HTML文档,然后会请求样式CSS文件和JS文件,然后JS文件里面会发起请求一些API,然后在HTML文档上做操作,丰富网页的内容和形式。
用puppeteer有一个好处是,它可以模拟真正的浏览器操作,因此可以抓取到用户真正看到的数据。
安装puppeteer需要下载chromium,所以会从Google网站上下载,所以国内用户可以通过cnpm来进行下载,这样会从一个国内源下载chromium。
但是实际用的时候效果并不好,我选择了抓取考拉海购的一个商品列表,puppeteer会长期无响应。可能是因为浏览器在不断根据滚动请求更多商品数据,不会停止,而且也下载了很多css文件,耗时很长。
- 使用语言:nodejs
- 用途:仿真模拟浏览器操作
- 优点:可以抓出js渲染出的数据
- 缺点:需要下载的数据量很大
0x02 requests

http://docs.python-requests.org/en/master/
requests是一个常用的Python库,可以用于发送HTTP/HTTPS请求。Python标准库里有一个urllib,不过API不够人性化,所以有人就开发了requests,宣称是HTTP for humans。
使用方式就是先建立一下Session,然后使用Session的.get()方法请求对应url
- 使用语言:Python
- 用途:发起HTTP请求
- 优点:简单易用
- 缺点:作为一个发包器没啥缺点
0x03 beautifulSoup

https://www.crummy.com/software/BeautifulSoup/bs4/doc.zh/
抓到原始数据后,只是一个html文档或者一个json串,这时候还不太容易直接从html文档中提取数据,因此需要一个工具通过操作API,能够迅速定位到文档中的特定位置的信息。beautifulSoup就是一款这样的工具,可以用简单的API操作读取html文档或者xml文档特定节点的特定数据。
使用BeautifulSoup时,感觉跟xPath有点像,然后就查阅了一点资料,发现却是有拿这个东西跟xPath的库lxml相比较的,得出的结论就是beautifulSoup更加易用,但是效率较低。
此外还有一个问题就是,我在抓取小红书的数据时,商品详情中的数据都是存储在一个INITIAL_SSR_STATE的js变量中的,这段js的数据是后端生成的,所以发现是个标准的json字符串,可以直接截取下来用Python的json库读出来。但是如果它不标准的话,或者是其他js代码,可能用beautifulSoup没有多大用,这一点,看了一个帖子里面提到了selenium这个前端测试工具,感觉可以用来读js内容。
后来又发现nodejs的cheerio包很适合做这项工作,特别是知道用$操作selector,不过没有尝试。
- 使用语言:Python
- 用途:解析HTML内容
- 优点:简单易用
- 缺点:效率低,对js没有很好的解决办法
0x04 Tor
![]()
在抓小红书商品数据时,我先获取了一些商品id,然后继续请求商品数据时,商品抓了20个,突然发现所有的商品抓取全都403了,原来是被反爬虫机制抓住了,直接被封禁了IP,当时我直接用了公司的wifi访问的,公司的wifi就一下子上不了小红书了,手机APP也打不开,换到4G才行,惊了一身汗,还好过了几个小时就恢复了,于是就想小心翼翼地去挂代理。
一开始先找了些免费代理的网站,但效果都极差。于是我想到了以前做安全时听说过的工具Tor,可以用于匿名浏览网页,然后搜索了一下相关的东西,果然找到了一篇文章。
http://www.cnblogs.com/likeli/p/5719230.html
洋葱一层层的,原理上应该就是跳了多级代理的方式,根据文章中的教程挂上了以后就会1分钟换1个代理,只要结合privoxy在requests库中指定本地开启的socks代理就可以了,查询了一下自己的IP,发现已经到了世界的一个随机的角落。
不过很可惜的是,这款工具“无法在中国大陆”使用,我也是为此特地“出国”才用上的,可惜可惜,想用这款工具的同学,需要自备护照,签证和机票。
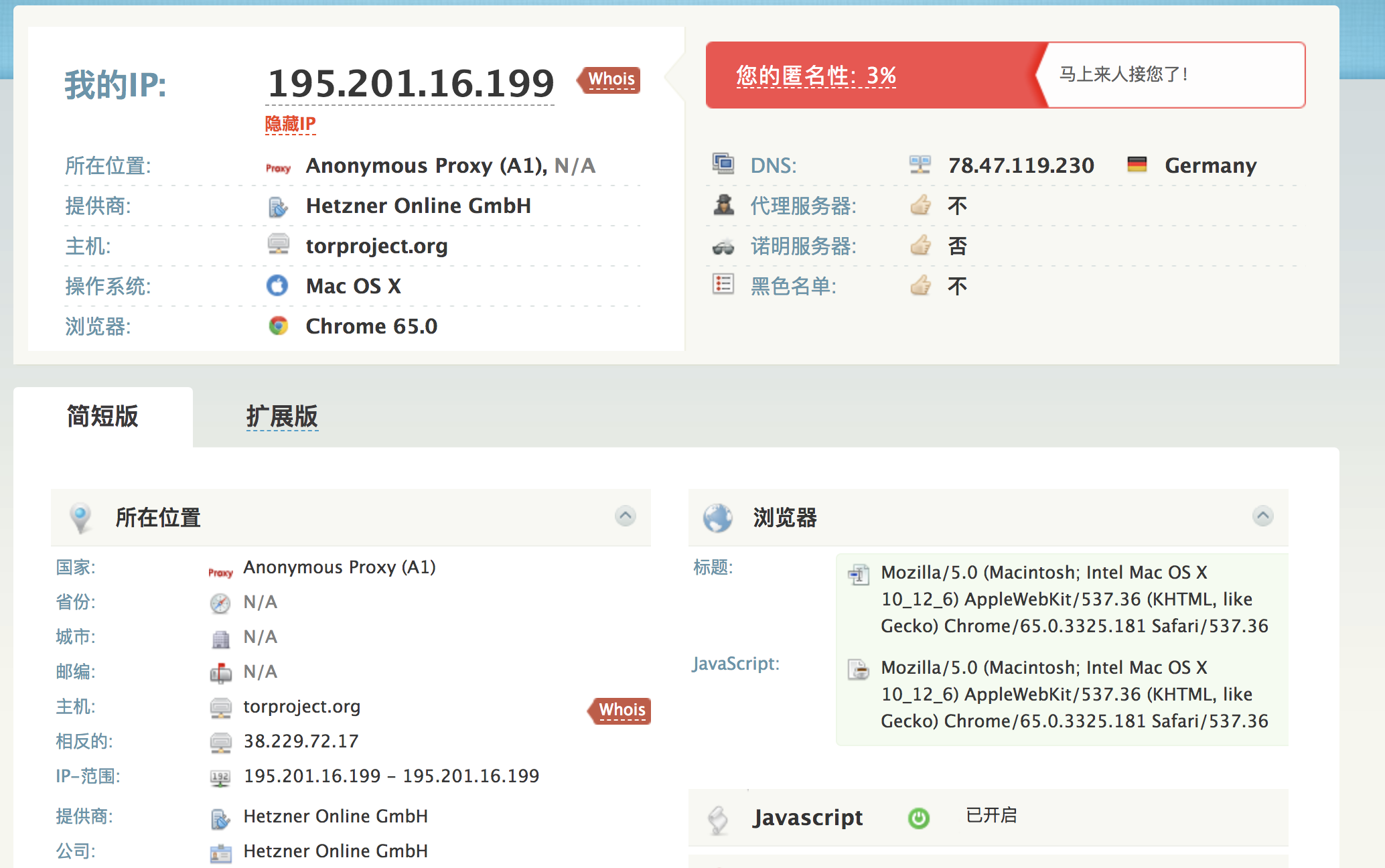
查询了一下自己的IP,发现自己已经穿越到了德国,这个网站的提示也非常嘲讽:马上来人接您了!
所以看到的同学千万不要用这个方法干违法乱纪的事,要找还是找得到您的。
这个方法除了要出国之外,还有个问题就是如果要连接国内的网站会非常缓慢,抓取数据可能经常会断连,所以需要在爬虫中做好异常处理。
- 使用语言:没有
- 用途:匿名代理
- 优点:可以解除IP封禁限制
- 缺点:需要出国使用,连接国内网站较慢
以上这些就是我最近探索的全部内容了,谢谢大家。
请问有源代码吗?
image_url = ‘https://www.xiaohongshu.com/discovery/item/%s’ % id
response_html = qq.get(image_url)
无法获取到整个html数据,就算加了headers如下也不行,qq.get(image_url, headers=headers):
headers = {
‘Accept’: ‘text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8’,
‘user-agent’: ‘Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3423.2 Safari/537.36’,
# ‘referer’: ‘https://www.instagram.com/’,
“Host”: “www.xiaohongshu.com”,
“Connection”: “keep-alive”,
‘Accept-Encoding’: ‘gzip, deflate, br’,
‘Accept-Language’: ‘zh-CN,zh;q=0.9’,
}
qq.get是什么东西?来自什么库?我记得我抓小红书数据时好像对header没什么要求,只抓一两次完全抓得到,只不过速度比较快发了几十次以后ip就被封禁了,这个时候就要架设Tor代理了,不断换IP。